
Proficiency with XPath expressions for accurate element identification is essential for efficiently handling XML and HTML texts. With the help of XPath, developers may identify specific items in the document tree according to their properties, relationships, and structure. Through comprehension of XPath syntax, which encompasses the utilization of slashes, wildcards, predicates, and functions, professionals may create expressions customized to meet their specific requirements. When it comes to element identification, XPath provides a flexible toolbox. Nodes can be chosen according to their names, properties, or locations within the document.
Table of Contents
Furthermore, navigating the document hierarchy is made simple by being familiar with axes like child, parent, ancestor, and descendant. Testing and debugging XPath expressions are crucial in the mastering process to ensure precision and consistency in element selection. Practitioners handling XML documents with namespaces also need to consider namespace issues.
What is XPath?
The sophisticated query language, XPath, or XML Path Language, is used to navigate and select items within XML documents. It offers a defined method for navigating the XML document’s hierarchical structure, making it possible to precisely identify and retrieve particular data pieces. Developers accustomed to working with directory structures will find XPath straightforward since it functions based on a path-like syntax similar to file system paths.
What makes XPath work is its expression language. Predicates, axes, and placement steps provide the path to the required items in the XML text. Axes indicate the relationship between nodes, such as parent-child or ancestor-descendant, whereas location steps show the path to a specific node. Predicates filter nodes by certain criteria, such as attributes, values, or document locations.
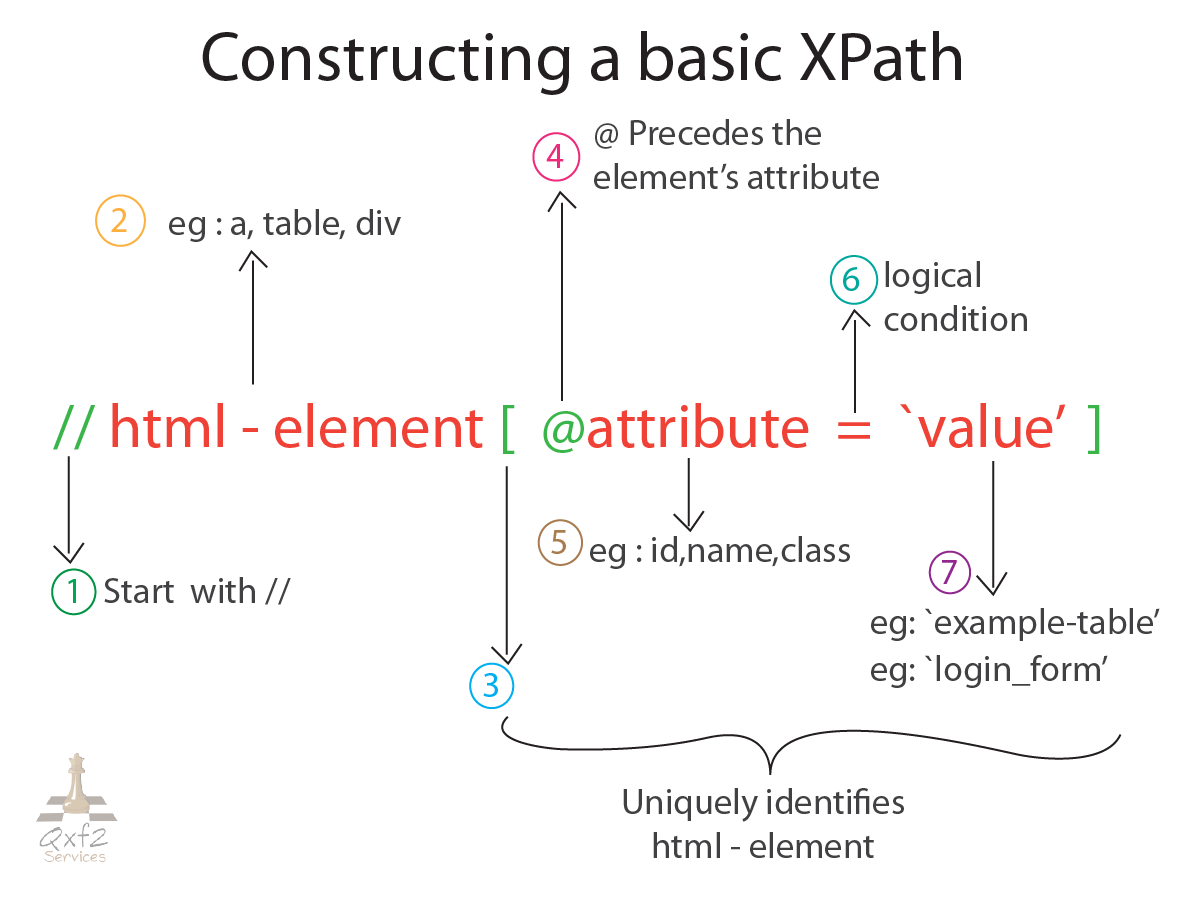
Developers may accomplish many things with XPath expressions, such as traversing intricate document structures, extracting data for additional processing, and querying XML data. XPath expressions offer a versatile and effective way to interact with XML documents, enabling developers to change and extract data with ease and accuracy. XPath is widely used in many disciplines, such as web scraping, data extraction, and XML transformation.
Types of XPath
XPath, a powerful language for navigating XML and HTML documents, can be categorized into three main types based on their usage and structure:
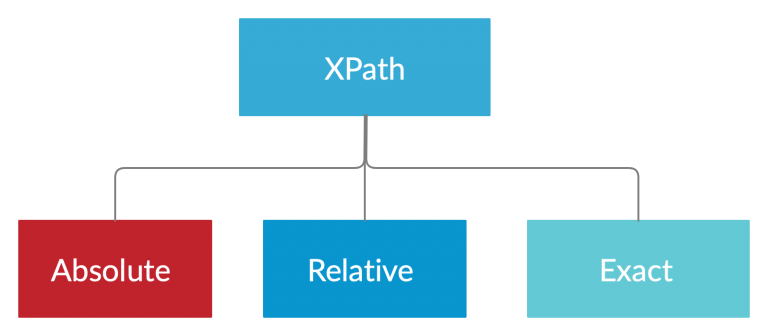
- Absolute XPath:
In an XML or HTML document, Absolute XPath indicates the whole path from the root node to the desired element. The hierarchy is indicated by the series of element names following the single forward slash (/), representing the root node. /html/body/div[1]/form/input[2] is one example. Absolute XPath is appropriate when the document structure is unchanging since it gives a precise route to the element. In contrast to relative XPath, it tends to be longer and less flexible and is prone to breaking if the document structure changes.
- Relative XPath:
Relative XPath specifies the route to the target element concerning any node in the document. The search for elements anywhere in the document starts with a double forward slash (//), followed by the elements or attributes that lead to the target. Take //input[@id=’username’] as an example. In terms of adapting to modifications in the document structure, relative XPath is more versatile. Compared to absolute XPath, it is shorter and more straightforward to read. On the other hand, it could pick up unwanted components and suffer from performance issues with huge texts if not designed carefully.
- Exact XPath:
Exact XPath, often called partial XPath or shortened XPath, concentrates on particular characteristics or components that uniquely identify the destination without giving the whole route. Usually, the beginning of the absolute or relative XPath phrase is omitted; instead, a reference to a specific attribute or element is used. Consider //*[@id=’username’]. Targeting particular properties or components without defining the whole route is simple and efficient using Exact XPath. That being said, it is less accurate than absolute or relative XPath expressions and mainly depends on characteristics for identification, which might change or become unavailable.
To navigate and select items inside XML and HTML documents efficiently, one must know the distinctions between and suitable use cases for each XPath expression.
What is Element Identification?
The technique of precisely locating particular elements inside XML or HTML documents is called element identification. The process entails navigating the document’s hierarchical structure using XPath expressions and choosing the desired elements according to some criteria, including element names, attributes, relationships, and locations within the document tree.
For several activities, including data extraction, web scraping, XML manipulation, and document processing, precise element identification is essential. Developers may precisely target items using XPath expressions and effectively and efficiently retrieve pertinent data.
Developers must be familiar with XPath syntax, which includes the usage of slashes, wildcards, axes, and predicates, to master element identification using XPath expressions. They must also be skilled in creating customized XPath expressions to meet their unique needs, whether those needs include picking components according to their names, characteristics, or locations on the page.
Testing and debugging XPath expressions are crucial in the mastering process to ensure precision and consistency in element selection. Developers may become more proficient in navigating intricate document structures and confidently extracting data by practicing and experimenting with XPath. This will eventually improve the efficiency of their XML and HTML processing initiatives.
To leverage the capabilities of XPath testing using cloud-based platforms like LambdaTest. LambdaTest is an AI-powered test orchestration and execution platform that lets you run manual and automated tests at scale with over 3000+ real devices, browsers, and OS combinations.
How To Use the LambdaTest XPath Tester Tool?
When learning to use XPath expressions for accurate element identification, LambdaTest is a treasure. It provides an XPath tester tool within its cloud-based testing platform, enabling developers to quickly and efficiently evaluate XPath expressions against actual web pages. With the help of this tool, developers may instantly assess the performance of their XPath expressions and make necessary adjustments to ensure precise element identification.
It improves learning and expands comprehension of XPath principles. Developers may increase productivity and efficiency by streamlining the XPath expression testing process using LambdaTest’s platform. LambdaTest promotes developer teamwork by offering integration options for sharing and collaboration. This allows for exchanging information and group learning to master XPath expressions for accurate element identification.
Here’s a step-by-step guide on how to use the LambdaTest XPath tester tool:
- Go to the LambdaTest website by opening your web browser.
- Enter the URL: Enter the website URL you wish to test XPath expressions against in the URL input form at the top of the page. The given webpage will load into LambdaTest’s testing environment.
- Get to the XPath tester: Select the “XPath Tester” tab on the left sidebar to utilize the XPath Tester. The XPath tester tool will launch as a result.
- Enter XPath expression: Type the XPath expression you wish to test into the XPath input area. The XPath expression can be manually typed or copied from another source.
- Run the test: Select the “Run Test” button after inputting the XPath expression. The loaded webpage will be subjected to an XPath expression execution and results presentation by LambdaTest.
- View Results: The “Results” section, located underneath the XPath input field, will show the outcomes of the XPath expression test. A list of matched items with their corresponding values and attributes will be displayed.
- Refine or edit XPath: You can refine or edit the XPath expression and repeat the test until you get the desired results if it does not provide the expected results.
- Examine Elements: LambdaTest offers an “Inspect Element” choice next to every result that matches. By selecting this option, you can quickly check the integrity of the information by highlighting the related piece on the webpage.
- Export Results: By selecting the “Export Results” option, you may export the XPath expression test results if necessary. This enables you to store the outcomes for further review or record-keeping.
- Precise Results: All you have to do is click the “Clear Results” button at the bottom of the “Results” section to start a new test and remove the previous ones.
These instructions will help you discover and extract items for web scraping, automation, and other uses for the LambdaTest XPath tester tool. With this tool, you can validate and test XPath expressions against web pages quickly and effectively.
Why do we need to master XPath Expression for precise element identification?
It is crucial to learn XPath expressions for accurate element identification for several reasons:
- Data Extraction: Developers may effectively extract particular data items from XML or HTML documents by using XPath expressions. Developers may obtain pertinent data for additional processing or analysis through precise identification and targeting of the intended parts.
- Web Scraping: XPath expressions are essential for discovering and extracting specific material from web pages in web scraping operations. Gaining proficiency in XPath enables developers to explore the document’s structure and retrieve data precisely, increasing the efficacy of web scraping initiatives.
- Document Manipulation: Programmatic navigation and manipulation of XML documents is accomplished through XPath expressions. Correctly executing activities such as updating, removing, or rearranging items inside the document depends on correct element identification.
- Automation: XPath expressions frequently use automation testing tools and scripts to communicate with web components. Developers may achieve more accuracy and dependability when automating repetitive processes like form filling, button clicking, and page content verification by becoming proficient with XPath.
- Data Integration: Data integration processes frequently use XPath to extract and manipulate data from several sources. By ensuring that the correct data is retrieved and incorporated into the target system, precise element identification preserves the consistency and quality of the data.
- Efficiency and Performance: Developers may create performance-optimized XPath expressions and speed up data retrieval and processing by precisely identifying elements. This effectiveness is significant when working with complicated or large-sized papers.
To sum up, developers may effectively traverse, extract, and manipulate components within XML and HTML documents by learning to use XPath expressions. Precise element identification is critical to accomplishing operations related to automation, online scraping, data integration, and data extraction. It improves performance by increasing accuracy, efficiency, and overall efficiency.
Conclusion
In conclusion, developers working with XML and HTML documents will find it invaluable to learn how to identify elements using XPath expressions precisely. Developers may effectively extract and modify data from structured documents by mastering XPath expression composition, utilizing tools such as LambdaTest for testing, and comprehending XPath syntax. Proficiency with XPath guarantees precision and dependability in document processing and improves web scraping, data extraction, and automation jobs. Developers may fully utilize XPath for accurate element identification by committing to study and practice, enabling them to navigate complicated document structures confidently.
Read our blogs Magazines Victor






